HHNTube - AWS basierter Youtube Klon
In der Vorlesung „Cloud Computing“, haben Laura Ködel und ich uns als Aufgabe gesetzt, einen Youtube Klon zu bauen. Für die Umsetzung sollten wir von möglichst vielen AWS Services gebrauch machen.
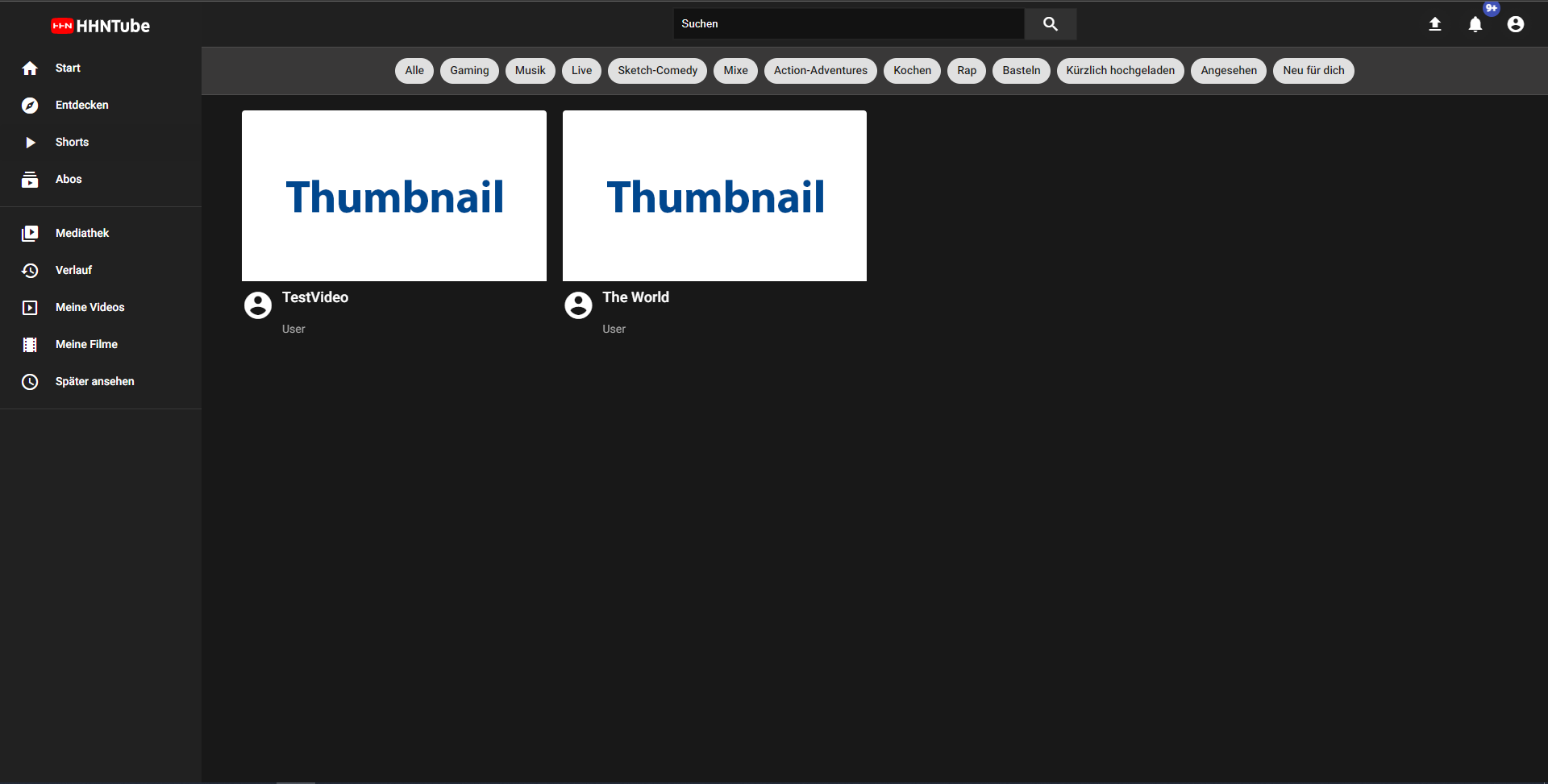
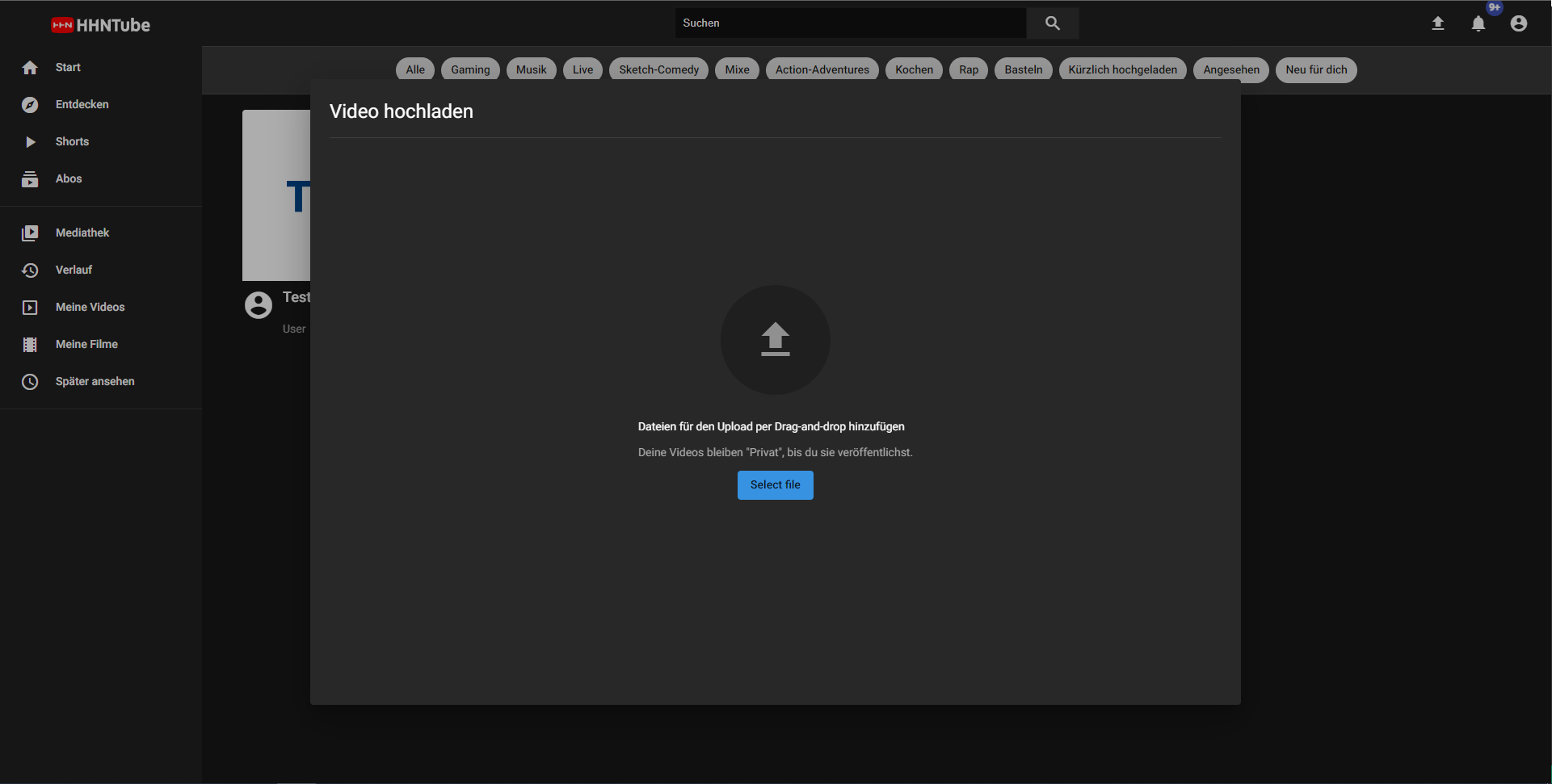
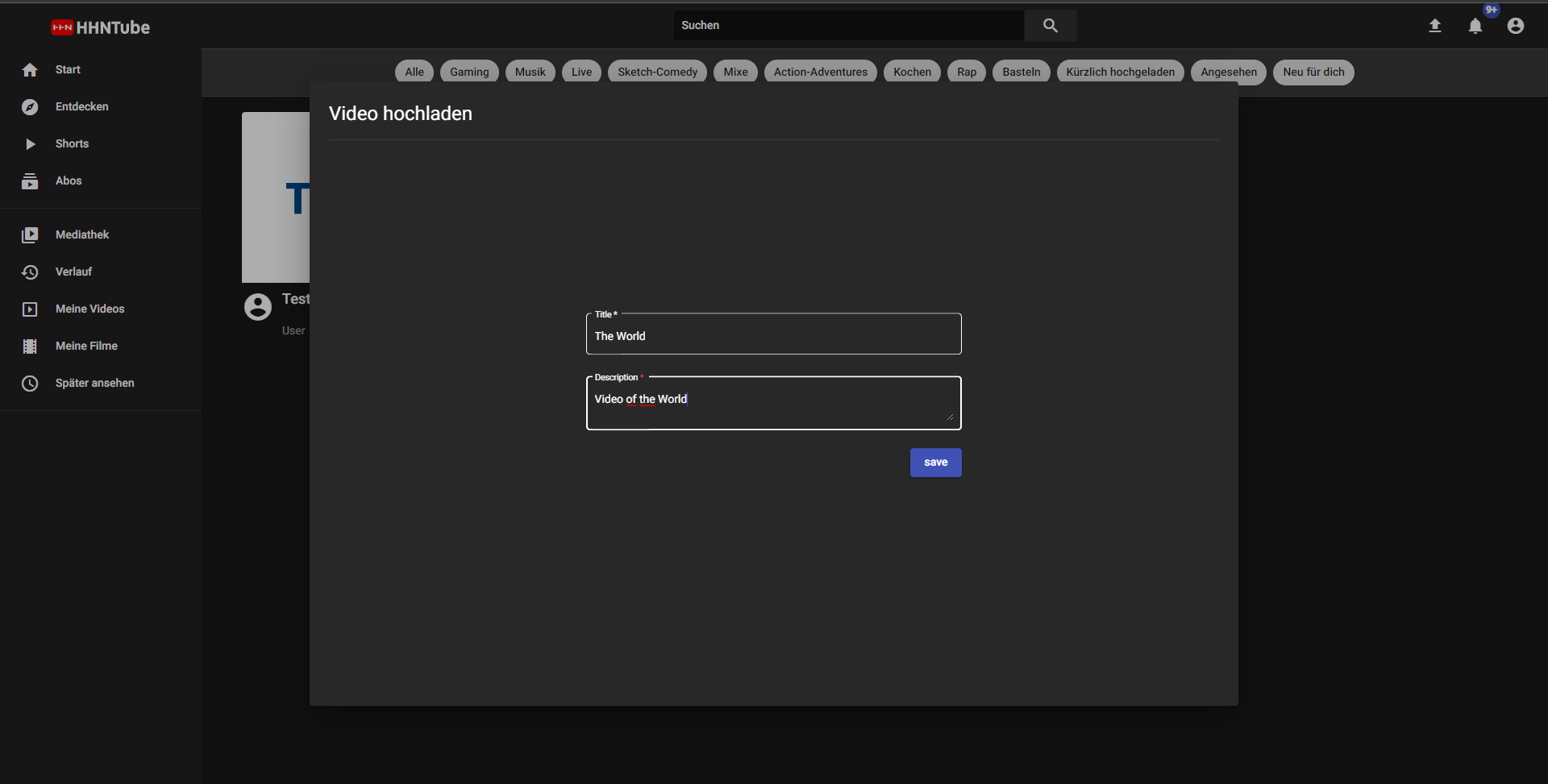
Mit der Streaming-Anwendung können Nutzer Videos oder Filme, die sie selbst erstellt haben, hochladen und ansehen. Der Nutzer muss lediglich einen Titel und eine Beschreibung zusammen mit dem Video angeben. Die hochgeladenen Videos werden in einem S3-Bucket gespeichert und in der Datenbank referenziert, so dass sowohl eigene Inhalte als auch Videos von anderen Nutzern angesehen werden können. Um diese Funktion nutzen zu können, muss sich der Nutzer registrieren und seine Daten validieren. Nach der Anmeldung in einem Konto wird die Benutzeroberfläche der Anwendung angezeigt. Dabei bietet die Benutzeroberfläche ein ansprechendes Design. Alle Filme werden auf einer Übersichtsseite aufgelistet, auf der der Nutzer den Titel und einen Thumbnail des präsentierten Videos sehen kann.
Architektur
Innerhalb der AWS-Streaming-Anwendung werden die folgenden Services verwendet:
Service | Function |
Amazon IAM | Service access management |
Amazon S3 | Assets and static website |
Amazon API Gateway | Interface to execute lambdas |
Amazon DynamoDB | Storage for movies |
AWS Lambda | Execution of functions |
Amazon Cognito | User management and login |
Amazon S3 (Simple Storage Service) bietet einen einfachen Objektspeicher zum Speichern und Verarbeiten jeglicher Art von Daten. In diesem Projekt wird S3 als Basis für die Speicherung von Filmdaten verwendet, so dass diese anschließend von Lambda-Funktionen zur Verfügung gestellt und von ihnen verwendet werden können. Mehrere Instanzen von S3-Ressourcen, sogenannte Buckets, können implementiert werden, um eine unbegrenzte Anzahl von Objekten darin zu speichern. Das Web-Interface wird ebenfalls in einem seperatem S3 Bucket gespeicht und öffentlich gemacht. Die komplette Konfiguration der Infrastuktur, wurde mit Hilfe von Terraform beschrieben und anschließend automatisch deployed.
Das Frontend der Website wurde mit Angular programmiert. Angular basiert auf TypeScript und wurde speziell für die Erstellung von Webanwendungen entwickelt. Um den Zugriff auf die Webseite zu kontrollieren, nutzen wir den AWS-Service Cognito. Dort werden die Benutzer so verwaltet, dass nur registrierte Benutzer die Webseite sehen können. Wenn sich ein neuer Benutzer anmeldet, wird eine E-Mail mit einem Verifizierungscode verschickt. Nach Eingabe des Codes ist der Benutzer verifiziert und kann sich anmelden, um die Webanwendung zu sehen und zu nutzen.
Die Verweise auf die Videos werden in einer DynamoDB-Datenbank gespeichert. Der DynamoDB-Dienst von AWS bietet eine NoSQL-Schlüsselwertdatenbank mit unbegrenzten Kapazitäten und schnellem Datenzugriff. Für dieses Projekt besteht die Datenbank aus einer Tabelle namens „video-table“. Ein Eintrag in der Tabelle entspricht einem „Video-Element“, das durch die Video-ID, den Titel, die Objektspeicher-URL und die ID des Hochladenden beschrieben wird. Die Struktur der Tabelle ist auch in der folgenden Grafik dargestellt.

Lambda ist ein Dienst für die Ausführung von Code, der in Form eines Zip-Archivs bereitgestellt wird. Die Ausführung von Lambda-Funktionen kann durch verschiedene Ereignisse ausgelöst werden. Die grundlegende Funktionalität ist in der folgenden Abbildung dargestellt, in der eine Lambda-Funktion durch einen Upload in einen S3-Bucket ausgelöst wird.
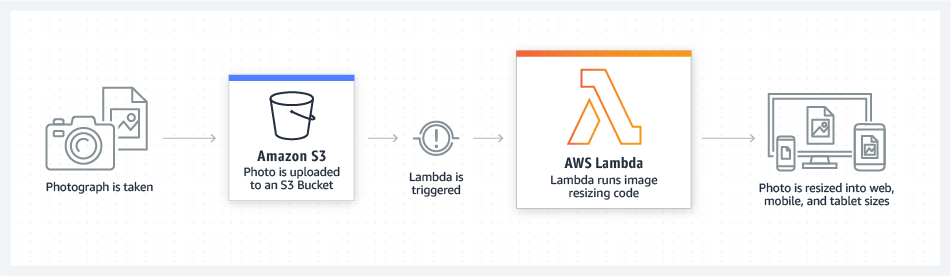
Für dieses Projekt werden die Lambda-Funktionen in NodeJS geschrieben. Sie bieten verschiedene Funktionen wie die Rückgabe aller Filmreferenzen, das Erstellen der Datenbankeinträge oder das Abrufen der Video-URL aus dem S3-Bucket.
Der IAM-Dienst kümmert sich um die Zugriffsverwaltung für die Dienste und kann so konfiguriert werden, dass gesteuert werden kann, wer unter welchen Bedingungen auf welche Dienste und Ressourcen zugreifen darf. In diesem Fall ermöglicht er den Lambda-Funktionen den Zugriff auf die S3-Buckets sowie auf die DynamoDB, wo Rechte vergeben werden, um zum Beispiel einen neuen Datenbankeintrag zu erstellen.
API
Zu guter Letzt verwenden wir den API-Gateway-Dienst, um eine Schnittstelle für den Zugriff auf die Dienste von außen bereitzustellen. Das API-Gateway erstellt eine RESTful-HTTP-basierte API, um Standard-HTTP-Methoden wie GET, POST, PUT, PATCH und DELETE bereitzustellen. Letztendlich regelt es also den Datenverkehr zwischen der Webanwendung und den AWS-Services, wie in der folgenden Abbildung zu sehen ist.
Die vom API-Gateway innerhalb dieser Anwendung bereitgestellten Endpunkte werden in der folgenden Tabelle erläutert.
Uploads: GET | Return a pre-signed URL, which allows to user to directly upload to the S3 Bucket |
Videos: POST | Create a video entry in the database |
Videos: GET | Get all videos entries from the database |
Videos/{id} POST | Updates a video in the database by its ID |
Videos/{id} GET | Gets a video from the database by its ID |
Architektur Übersicht
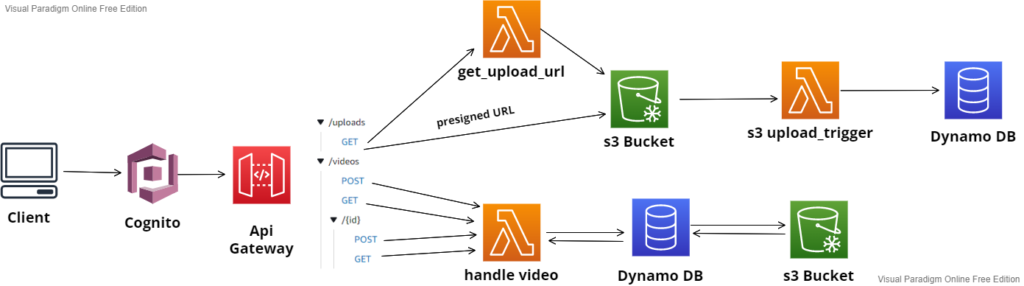
Um die beschriebenen Dienste in einen Zusammenhang mit der geschriebenen Anwendung zu bringen, veranschaulicht das folgende Bild die Dienste, die innerhalb der Anwendung ausgeführt werden. Der Einfachheit halber wird der Amazon IAM Service nicht dargestellt.
Der Client sendet eine Anfrage an das API Gateway über Cognito. Um ein neues Video hochzuladen, wird die Lambda-Funktion get_upload_url angefordert, und das Video wird in einem S3-Bucket gespeichert, wo es eine presigned URL erhält. Der neue Inhalt im S3-Bucket löst die Lambda-Funktion s3_upload_trigger aus, die einen neuen Eintrag in der Datenbank erstellt, um die Informationen über das neue Video zu speichern. Um ein Video abzuspielen, führt die Anfrage des Clients vom API-Gateway die Lambda-Funktion handle_video aus, die die in der Datenbank gespeicherten Informationen verwendet, um auf das passende Video im S3-Bucket zuzugreifen.
Skalierbarkeit
Die Skalierbarkeit der entwickelten Streaming-Plattformen ist theoretisch unbegrenzt. Durch die Verwendung von API-Gateway und Lambda-Funktionen gibt es von dieser Seite aus keine konkreten Grenzen. Allerdings haben die Dienste vordefinierte Limits für verschiedene Parameter, die von AWS kommen. Für die verwendeten Services sind einige Beispiele dieser Quoten in der nächsten Tabelle zusammengefasst, alle zu erläutern würde den Rahmen dieses Textes sprengen. Einige dieser Grenzen können erweitert werden, daher muss eine Quotenerhöhung bei AWS beantragt werden.
Service | Quotas |
AWS S3 | 5 GB part size 100 Buckets |
AWS Lambda | 1 000 000 requests/month 1 000 concurrent executions |
Amazon IAM | 5000 users |
Amazon DynamoDB | 50 concurrent operations 256 tables |
Amazon API Gateway | 1 000 000 calls/month |
Amazon Cognito | 1 000 user pools 1 000 apps per user pool |
Ein weiterer Flaschenhals in Bezug auf die Skalierbarkeit der Lösung wird durch die System- und Hardwarebeschränkungen eingeführt. Die Leistung – und damit auch die Skalierbarkeit – der Anwendung hängt von der Größe und Rechenleistung der Hardware der verwendeten Server ab. Da AWS auf Amazon-Servern läuft, ist die Möglichkeit, an diese Grenzen zu stoßen, sehr sehr gering.
Tooling
Developer Workflow
Der Entwickler hat die Möglichkeit, Lambda-Funktionen komplett lokal zu entwickeln und zu testen. Die in Node geschriebenen Lambda-Funktionen werden in einer beliebigen IDE entwickelt und nach Fertigstellung + Abschluss der Tests committed und in den entsprechenden Git-Zweig gepusht. Danach werden alle Tests innerhalb der CI-Pipeline getestet und bei Bedarf auf AWS bereitgestellt. Da die Tests automatisch in ein Docker-Image verpackt werden, kann der Entwickler die Tests unabhängig von der Entwicklungsumgebung ausführen
Docker Stack
Der Docker-Stack besteht aus zwei Containern. Der erste Container wird aus einer benutzerdefinierten Docker-Datei erzeugt. Diese basiert auf einem bereits vorhandenen Node-Image. Zusätzlich werden alle geschriebenen Lambda-Funktionen einschließlich der Testdateien in dieses Image kopiert. Beim Starten des Containers werden alle Tests mithilfe desTestframeworks Mocha + Chai getestet. Das Ergebnis der Tests wird nach Fertigstellung an die Pipeline übergeben, so dass sichtbar wird, ob die Tests erfolgreich waren.
Der zweite Container enthält eine lokale Version der AWS Dynamo DB, die eine Verbindung zu den Lambda-Funktionen des anderen Containers herstellt.
Beide Container werden über ein Docker Compose-Skript im gleichen Netzwerk gestartet. Um sicherzustellen, dass die DynamoDB vor der Ausführung der Tests gestartet wird, werden die Tests mit einem Startskript gestartet. Dieses Skript startet ein weiteres Skript, das den Prozess anhält, bis die Datenbank gestartet ist. Erst dann werden die Tests ausgeführt.
CI-Pipeline
Mit Terraform nutzt die Anwendung den Infrastruktur as Code Ansatz. Alle Dienste und Funktionen werden in mehreren Terraform-Dateien konfiguriert, die eine einfache Bereitstellung von Änderungen ermöglichen. Wenn eine Änderung veröffentlicht werden soll, werden nur die Befehle „terraform init“ und „terraform apply“ benötigt, um die Cloud-Anwendung mit der neuen Funktionalität zum Laufen zu bringen. Zusammen mit der kontinuierlichen Integrationspipeline auf GitLab werden die Terraform-Befehle automatisch ausgeführt, sobald Änderungen als Commit in das Repository gepusht werden. Die Build-Pipeline enthält auch die Softwaretests für die Lambda-Funktionen. Um die Pipeline auszuführen, wurde ein externer Runner konfiguriert, der auf einem separaten Server läuft. Dies war notwendig, da die Gitlab-Instanz der Hochschule Heilbronn aus Sicherheitsgründen keine Docker-Container erstellen darf. Der zweite Runner ist ein Shared-Runner und wurde von der Hochschule zur Verfügung gestellt. Die Auswahl des Runners wird in den Stages mit Hilfe von Tags definiert.

Nach der Ausführung des Tests werden die notwendigen Terraform-Funktionen automatisch als Propagation für das Deployment ausgeführt.
Das eigentliche Deployment und Destroying erfolgt erst im Master. Dies geschieht nur durch einen zusätzlichen manuellen Klick in der Pipeline durch den Benutzer. Auf diese Weise kann die Anwendung vollautomatisch getestet und deployed werden.
Lessons Learned
Im Rahmen dieses Projekts konnte man viel über die Entwicklung einer Cloud-Anwendung auf AWS und über Terraform lernen. Es war überraschend zu sehen, wie viele Dienste auf AWS verfügbar sind und welche Möglichkeiten sich daraus für die Entwicklung einer Anwendung ergeben. Sowohl die Dienste als auch Terraform sind einzeln gut dokumentiert, aber meist war es kompliziert und zeitaufwändig, Ressourcen zu finden, um den gewünschten Dienst mit der benötigten Funktionalität in Terraform zu konfigurieren. Außerdem war es manchmal eine Herausforderung, die richtigen Ressourcen und Komponenten zu finden, die in terraform eingebunden werden sollten, und wie man sie verbindet, damit der Dienst das tut, was erwartet wird.
Das gesamte Infrastructure-as-Code-Konzept ist sehr gut und für große Anwendungen geeignet, wie es bei Cloud-Lösungen normalerweise der Fall ist, aber für kleine Anwendungen wie die in diesem Projekt entwickelte scheint es zu viel zu sein. Andererseits ist die Infrastruktur, sobald sie richtig konfiguriert ist und alle Komponenten miteinander verbunden sind und funktionieren, zuverlässig und einfach zu implementieren. Das war ein weiterer sehr interessanter Teil dieses Projekts – einen Eindruck von der Leistungsfähigkeit von terraform zu bekommen. Mit nur zwei Zeilen Terraform-Befehlen ist jede Anwendung einsatzbereit und läuft. Die Fehlermeldungen sind meist eindeutig und führen direkt zum Problem, was die Fehlersuche zu einer angenehmen Aufgabe macht – zumindest die meiste Zeit und wenn es einen tatsächlichen Fehler in terraform gibt.
Einige Probleme, die nicht so einfach zu finden waren, betrafen das Setzen der richtigen Berechtigungen für Ressourcen und Lambdas.
Außerdem hat die Implementierung der CI-Pipeline sowie der Tests für die Lambda-Funktionen viel Zeit in Anspruch genommen. Hier stießen wir auch auf diverse Probleme mit fehlender Dokumentation und irreführenden oder nicht vorhandenen Fehlermeldungen, wenn es um die Zusammenarbeit von terraform und einem anderen System geht.
Aber natürlich haben wir durch all diese Herausforderungen eine Menge über die Entwicklung und Bereitstellung einer Cloud-Anwendung gelernt.
Blog

🎅✨ Der Weihnachtsmann ist real! KI macht’s möglich. 🤖✨
- 23 Dezember 2023
- Lukas Ertl

Der Selbst-Test Gewinnt den Preis für das beste Projekt
- 30 September 2020
- Lukas Ertl
Privacy Overview
Necessary cookies are absolutely essential for the website to function properly. This category only includes cookies that ensures basic functionalities and security features of the website. These cookies do not store any personal information.
Any cookies that may not be particularly necessary for the website to function and is used specifically to collect user personal data via analytics, ads, other embedded contents are termed as non-necessary cookies. It is mandatory to procure user consent prior to running these cookies on your website.